
SAS Data Step Merge Explained
March 21, 2022
8 min
This article explains the data step merge in SAS, including the meaning of a merge, the preliminary prerequisites for every dataset obtained in a merge, merge syntax, and the numerous types of merges accessible to SAS administrators and users.
Merging combines observations from two or more SAS data sets into a single observation in a new data set.
When you merge datasets without a BY statement, SAS merges the first observation from all sets of data indicated in the MERGE statement into the new data set’s first observation, the second observation from all data sets into the new data set’s second observation, and so forth.

One-to-One Merge
The number of observations in the new data set equals the number of observations in the largest data set indicated in the Merging statement in a one-to-one merge.
data combine;merge data1 data2;run;
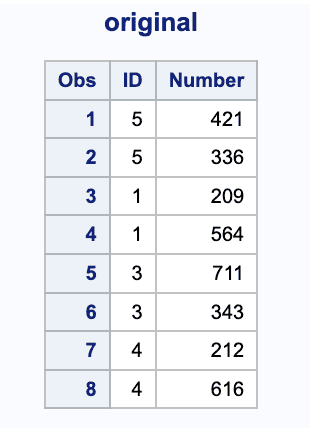
SUMMARY
A one-to-one merge combines observations based on their position in the data sets and the number of observations in the new data set equals the number of observations in the largest data set you name in the MERGE statement.
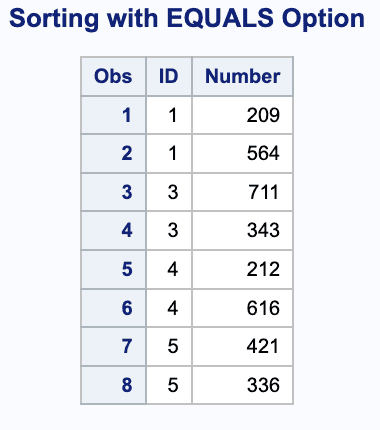
A match-merge combines observations based on the values of one or more common variables. If you are performing a match-merge, use the MERGE and BY statements.
In the following example, two data sets are match-merged by the value of the variable Id.
data combine;merge data1 data2;by id;run;

Match Merge
Set the system “option”:(Optional) MergeNoBy = ERROR; this ensures that the log will show an error message if a MERGE statement is used without a corresponding BY statement.
Set the system option(Optional): By using MSGLEVEL= System Option and setting it to msglevel = I; ensures additional messages are written to the SAS log.
Use a BY statement(Required): in the data step to force SAS to put values into a single observation combining data from observations in the source datasets where the BY variable has the same value; ·
Sort both the datasets (Required) by the matching variables listed in the BY statement; if the datasets are not sorted correctly, you will get error messages in the log
When you merge tables, you might have some rows that don’t have a corresponding match in the other table. For example, Honda Accord is present in the Mfg dataset but not in the Cars dataset. Similarly, isuz max is present in the Cars dataset but not in the mfg dataset.

MFG Dataset

Cars dataset
What happens to those non-matching rows in the data step merge?
data Mergedata;merge mfg cars;by mfg;run;
Although both input tables have 4 rows, the output table Mergedata has 6 rows because it includes both Honda and isuz.

Merged data
The rows for Honda and isuz have missing values for the columns in the tables where they were not included.
The output dataset you create when you merge tables with non-matching rows might not be what you want. For example, suppose you only want to include cars that are on both tables. Or suppose you want to identify missing cars in one of the tables.
You can use the IN= dataset option to create temporary variables in the PDV that you can use to flag matching or non-matching values.

Identifying matches and nonmatches
The IN= dataset option follows one or more tables on the merge statement and names a temporary variable that is added to the PDV.
The IN= variables are included in the PDV during execution but are not written to the output table. Each IN= variable is associated with a particular table that the option follows.

PDV during the merge process
During execution, the in= variables are assigned a value of zero or one. Zero means that the table does not include the by column value for that row, and one means it does have the by column value.
 MFG Dataset
MFG Dataset
 CARS dataset
CARS dataset
Let’s see what these IN= variable values would look like for each row in our class two table. First, notice when the mfg was read from both input tables inMfg and incars are both one.

Merged Dataset

IN=Variables
For example, honda is only in the mfg table, so inCars is zero and inMfg is one.
And the opposite is true for isuz. So how can you use these IN= variables in your program to subset the output table?
For example, how could you include only the matching rows in your output table? You probably already know the answer, so let’s see if you get it right.
We’ll use the data step merge to combine two tables and identify non-matching rows. In the Mfg table, we have information about the Car Manufacturer, Model, and price. But what we don’t have is the mileage. However, that information is contained in the cars table.
So we would like to merge these two tables to include the mileage column with the mfg table.
In the previous example we saw, we have a total of 6 rows. So we will need to limit the rows in our output table to only those that match. In other words, we want to eliminate the non-matches.
The first step is to sort both datasets. So, we’ll sort the data by both mfg and model.
proc sort data=mfg;by mfg model;run;proc sort data=cars;by mfg model;run;
Okay, we’re ready now for the merge.
A Left Merge provides matched observations from two or more datasets while retaining all mismatched observations from the first (left) data set. For example, in the Venn diagram below, the coloured regions (Car Manufacturer and Car Mileage) represent a Left merge.

LEFT Merge
Remember, we would only like to include in our output table the 4 manufacturers and models that were in the cars table in our output table.
We can use the IN= data set option to control which rows are output.
So after the mfg table, we will add IN=, and we’ll create a variable called inMfg. This inMfg variable will be included in the PDV during execution. It will take on a value of either zero or one. The value will be one for a row that is read from the mfg table. Otherwise, it will be zero.
To subset, we will use inMfg=1. If the subsetting if statement is true SAS will continue processing the rest of the data step, including the implicit output.
proc sort data=mfg;by mfg model;run;proc sort data=cars;by mfg model;run;proc sort data=mfg;by mfg model;run;proc sort data=cars;by mfg model;run;data leftmerge;merge mfg(in=inMfg) cars;by mfg model;if inMfg;run;

LEFT Merge Example
Our final table below has 4 rows, the 4 rows included from the original mfg table. You’ll notice we have the additional column mileage_mps that was read from the cars table.
Using the IN= dataset option and the variables created in the PDV give you much control over determining what to do with matching or non-matching rows.
SUMMARY
Left Merge returns all rows from the left table and the matched rows from the right table.
A Right Outer merge provides matched information from two or more datasets while retaining all mismatched information from the next (right) set of data. The shaded regions (Manufacturers and Cars) represented by the Venn diagram below represent a Right Outer merge.
 RIGHT Merge
RIGHT Merge
The SAS Merge code shown below displays a right merge that picks “matched” manufacturers and models from the mfg and car databases depending on mfg variable(BY Variable), as well as all “unmatched” manufacturers and model from the cars database.
proc sort data=mfg;by mfg model;run;proc sort data=cars;by mfg model;run;data rightmerge;merge mfg(in=inmfg) cars(in=incars);by mfg model;if incars;run;

Right Merge Example
SUMMARY
Right join returns all rows from the right table, and the matched rows from the left table.
An inner join retrieves only the matched rows from the data sets/tables.
In the mfg and cars dataset, an inner join gives the result of manufacturer intersect cars, i.e. the inner part of a Venn diagram intersection. (See below image)
 INNER Merge
INNER Merge
We have used IN= options to get the common data using merge and only those observations where inMfg and inCars =1, are selected.
proc sort data=mfg;by mfg model;run;proc sort data=cars;by mfg model;run;data innermerge;merge mfg(in=inmfg) cars(in=cars);by mfg model;if inmfg and incars;run;

SUMMARY
Inner Merge/Join returns rows common to both tables or dataset.
A full merge returns all rows from the left table and the right table.

FULL Merge
The FULL JOIN is also the default type of JOIN in the MERGE statement, and it does not require temporary variables with IN option.
proc sort data=mfg;by mfg model;run;proc sort data=cars;by mfg model;run;data fullmerge;merge mfg(in=inmfg) cars(in=incars);by mfg model;if inmfg or incars;run;

Full Merge Example
SUMMARY
Full join returns all rows from the left table and the right table.
Suppose you have two tables avgtemp2016 and avgtemp2017. you want to merge. They have a common by column, but columns in both tables share the same name, and we want all columns in the output table.

Merging tables with matching column names
When we merged the tables, having the same column name in both the tables, DATA STEP MERGE takes variable “avgtemp” values from dataset avgtemp2017.
The value of common variables comes from the avgtemp2017 dataset. SAS reads a value from data set avgtemp2016, then reads a value from avgtemp2017 The value from the dataset avgtemp2017 is read last and overwrites the value read from data set avgtemp2016.
if you have enabled the system option msglevel=i, you would notice an additional message written in the log as below.
I"NFO": The variable AvgTemp on data set WORK.AVGWEATHER2016 will be overwritten by data set WORK.AVGWEATHER2017.
To ensure that the average temperature columns from both the 2016 and 2017 tables are included in the output table, you must first use the rename= data set option to give each column a unique name, and that will solve it.
data combine;merge avgWeather2016(in=a rename=(avgtemp=avgtemp2016)) avgWeather2017(in=brename=(avgtemp=avgtemp2017));by month;run;

Merged dataset
SUMMARY
When both the tables (data sets) have a similar variable name (other than the primary key), the Data Step MERGE statement will take values of the common variable that exist in the TABLE2 (Right table).
If the primary key in both the tables (data sets) have duplicate values, the Data Step MERGE statement will return a maximum number of values in both the tables.
data mfg;input mfg $model $price;datalines;benz b-class 10000bmw x6 15213bmw x4 13213suzuki winz 12457honda accord 14567;run;data cars;input mfg $model $mileage_mps $;datalines;benz b-class 12bmw x3 15.2bmw x1 15.5bmw x5 15.7suzuki winz 16isuz mux 14;run;proc sort data=mfg;by mfg model;run;proc sort data=cars;by mfg model;run;data Combined;merge mfg(in=a) cars(in=b);by mfg model;if a;run;
In this case, dataset mfg contains two duplicate BMW values, and dataset cars have three duplicate values for BMW. When we merge these two tables, it returns three BMW values since the maximum number is 3 in datasets mfg and cars.

Many-to-Many Merge
It’s worth noting that SAS provides a helpful note in the SAS log, which indicates that things might not be proceeding as we had intended.
“NOTE”: MERGE statement has more than one data set with repeats of BY values.
This method works as expected on data that has a one-to-one relationship. However, since the relationship of the data in this example has both a one-to-many and many-to-one relationship, you might get unwanted results.
For more details, refer to the SAS Paper MERGE Statement Has More Than One Data Set With Repeats of BY Values!
For example, merging an observation containing a student’s name with an observation having a date, time, and location for a conference, and it does not matter which student gets which time slot.
Therefore, a one-to-one merge is appropriate.
You must use a match-merge to merge with specific observations.
For example, when merging employee information from two different data sets, you must merge observations related to the same employee.
**Wrapping it all up**
This article provided an overview of the intriguing world of DATA step merges, including what a merge is, examples of various merge strategies, and how you may use the DATA step to combine two or more datasets.Although merging is one of the most frequently performed operations when manipulating SAS datasets, many problems can occur, some of which can be rather subtle.
Recommended “Reading”: Merge with “Caution”: How to Avoid Common Problems when Combining SAS Datasets.
Thanks for reading!
If you liked this article, you might also want to read 4 Methods to find values in one table that are in another table and Combining data Vertically in SAS (6 Methods)
Do you have any tips to add? Let us know in the comments?
Please subscribe to our mailing list for weekly updates. You can also find us on Instagram and Facebook.

