


Table Of Contents


Proc Contents is a useful tool for analyzing data in SAS. This article will show you how to use Proc Contents to view the structure of your data and learn how to create new variables using this tool.
There are various possibilities in determining the position of variables or columns (and other essential details comprising metadata) in SAS.
Below are some of the methods by which you can view the metadata information of a SAS dataset.
- The CONTENTS Procedure
- The DATASETS PROCEDURE
- SAS Dictionary Tables (used with PROC SQL - DICTIONARY.COLUMNS)
- SASHELP Views (can be used with PROC SQL and with the SAS DATA step VMACRO,VCOLUMN)
- %SYSFUNC (through MACRO functions )
- Variable functions (VTYPE,VFORMAT)
- SAS File I/O (ATTRN)
In this article, we’ll specifically describe the PROC CONTENTS procedure.
Summarizing Data with PROC CONTENTS
With the PROC CONTENTS procedure, you can generate summary information about the contents of a dataset, such “as”:
- The variables’ names, types, and attributes (including formats, informats, and labels)
- How many observations are in the dataset?
- How many variables are in the dataset?
- When was the dataset created or last modified?
- How many datasets exist in a library?
- Find the Character and Numeric variables in a SAS dataset.
PROC CONTENT is useful if you have imported your data from a file and want to check that your variables have been read correctly and have the appropriate variable type and format.
For example, you may wish to review whether there is no truncation of character variables or whether date variables are correctly read.
“Syntax”:
PROC CONTENTS DATA=sample;RUN;
A simple example of the Proc Contents Procedure
To view the metadata of a SAS dataset, specify the SAS dataset name in the DATA= option. The dataset name is optional, but specifying it brings clarity to the code.
To start with, let’s take a look at an example dataset. We’ll call our dataset “class”. If you do not specify a dataset, SAS will use the most recently created dataset by default.
“Example”:
data class(label='Copy of SASHELP.CLASS dataset' alter="wclass" type=datagenmax=4);length sex $6.;set sashelp.class;label name="Student Name";format sex $genderfmt.;format weight z5.2;run;/*Assigning formats and labels*/proc format;value $genderFmt 'M'='Male' 'F'='Female' Other='Error';run;/*Sorting dataset*/proc sort data=class(alter=wclass) nodupkey force;by age weight height;quit;proc sql;create unique index name on class(alter=wclass);quit;
proc contents data=class;run;

Observations - It is the number of observations (or rows) in the dataset. In the example of SASHELP.CLASS dataset contains 19 observations.
Variables - The number of variables (or columns) in the dataset. In the example of SASHELP.CLASS dataset contains five columns.
Indexes - The number of Indexes in the SAS dataset.
Observation Length - It displays the record size in bytes. The length of observation might not be the sum of the total of the variables’ lengths. There can be padding depending on the type of variables.
proc contents data=class noprint out=class_contents;run;proc print;var name varnum npos type length;run;
PROC CONTENTS shows an observation length of 40. PROC PRINT displays the internal layout of the variables within the observation where NPOS is the physical position of the first character of the variable in the data set.

Observation and Variable Boundaries
Numeric variables have a default length of 8 bytes whereas character variables are set in the program. If you take a look at the program, we had the length of Sex as 6 and the remaining variables have a length of 8.
The total=8+8+8+8+6=38 bytes, but the observation length is always shown as the multiples of 8 in the results so it is 40 instead of 38.
The difference is the 2 bytes of padding so that the next observation is aligned on a double-byte boundary within the disk page buffer.
For more details, see our article on Length and Precision of SAS Variables.
Deleted Observations - This attribute shows how many observations are marked for deletion in the data set. If an observation is deleted, SAS marks that observation as no longer existing—it is not actually removed from the data set at that time. If it were, the data set would be rewritten every time an observation was deleted. Instead, the data can no longer be accessed.
The count for Deleted Observations shows a missing value if you use the COMPRESS=YES option with one or both of the REUSE=YES and POINTOBS=NO options.
If your data set has a large number of deleted observations, it uses disk space unnecessarily and SAS might take longer to access your active observations. Deleted observations must still be read from the disk and logic must be used to skip them when returning active data. To remove the deleted observations from the data set, you can use a method such as [PROC COPY](“http”://documentation.sas.com/?cdcId=pgmsascdc&cdcVersion=9.4_3.5&docsetId=proc&docsetTarget=p0wpwv5w54k35gn11y3rpqusf5s3.htm&locale=en) to copy the data set and retain other data set attributes that you need.
Use this code to determine how many deleted observations are in each data set in a “library”:
ods output attributes=deleted(keep=member label2 nvalue2 where=(label2 contains'Deleted' and nvalue2 > 0) );proc contents data=lib1._all_;run;proc print data=deleted;format nvalue2 1.;run;
Compressed - Compression can decrease the disk space required to store a data set. Compressing data means fewer reads or writes are required to get or put the data from or to the disk. indicates whether the data set is compressed.
If the data set is compressed, the output includes an additional item, Reuse Space (with a value of YES or NO). This item indicates whether to reuse space that is made available when observations are deleted.
Sorted - This field indicates whether the data set is sorted. If you sort the data set with PROC SORT, PROC SQL, or specify sort information with the SORTEDBY= data set option, a value of YES appears here, and there is an additional section to the output.
Last Modified - The Last modification date and time of the dataset.
Protection - It shows whether the dataset is Password protected or not.
Max Generation - The Maximum number of generations the dataset holds. Read - SAS Generation Datasets
Label - The Descriptive Label of the dataset.
Data Representation - The format in which data is represented on computer architecture or in an operating environment. For example, character data is represented by ASCII encoding on an IBM PC.
Encoding is the encoding value and can be used to determine the Encoding of a SAS Data Set.
This part of the output lists the dataset’s variables and their attributes.

(#): The original order of the variable in the columns of the dataset. (PROC CONTENTS prints the variables in alphabetical order to name, instead of in the order that they appear in the dataset.)
- “Type”: Whether the variable is numeric (Num) or character (Char).
- “Len”: Short for “Length”; represents the width of the variable.
- “Format”: The format for the values of the variables when printed on the output window.
- “Informat”: The format of the variables used to read the data in SAS.
- “Label”: The name of the variable when printed in the output window. If your variables do not have labels, this column will be the same as the Variable column.
Index information of a dataset

- # indicates the number of each index. The indexes are numbered sequentially as they are defined.
- Index - displays the name of each index. For simple indexes, the name of the index is the same as a variable in the data set.
- Unique Option - indicates whether the index must have unique values. If the column contains YES, the combination of values of the index variables is unique for each observation.
- Nomiss Option - If a NOMISS option is specified while creating an index, this field will show whether the index excludes missing values for all index variables. If the column contains YES, the index does not contain observations with missing values for all index variables.
- # of Unique Values - It gives the number of unique values in the index.
- Variables names - It displays the variables in a composite index.
Sort Information of a Dataset

- Sortedby- indicates how the data are currently sorted. This field contains the variables and options you use in the BY statement in PROC SORT, the column name in PROC SQL, or the values you specify in the SORTEDBY= option.
- Validated- indicates whether the data was sorted using PROC SORT or SORTEDBY. If PROC SORT or PROC SQL sorted the data set, the value is YES. If you assigned the sort indicator with the SORTEDBY= data set option, the value is NO.
- Character Set - is the character set used to sort the data. The value for this field can be ASCII, EBCDIC, or PASCII.
- Sort Option indicates whether PROC SORT used the NODUPKEY or NODUPREC option when sorting the data set. This field does not appear if you did not use this option in a PROC SORT statement (not shown).
Proc Content options
Describing a SAS dataset gives us every information about the SAS dataset. You can use various options with the PROC Contents procedure to customize the information you need.
Using the _ALL_ Keyword
Instead of running PROC CONTENTS separately for each data set, we can use the ALL keyword to run;
PROC CONTENTS once and get all the variable information for all the data sets in the library.
The code snippet below will show all the datasets available in the WORK library.
proc contents data=work._all_;run;
The NODS option
The NODS option (“no details”) suppresses the printing of detailed information about each file when you specify the ALL option.
proc contents data=work._all_ nods;run;
Using the DIRECTORY and DETAILS Options
We have asked PROC CONTENTS for information about only one SAS data set. SAS provides the ability to display the contents information about all the files in our data library using ALL in place of the data file name.
When we do so, PROC CONTENTS also provides useful information about our SAS data library. If we want this useful data library information while wanting data file information about only one data file (that is, when we don’t use the _all_ feature), we can use the DIRECTORY option.
DIRECTORY option in the proc contents procedure prints a list of all SAS files in the specified SAS library. The DETAILS option includes information in the output about the number of rows, number of variables, and table labels.
proc contents data=macas.cars directory details;title 'Using the DIRECTORY and DETAILS Options';run;
Below are the additional details you get using the directory option.

DETAILS | NODETAILS
These two options are used along with the DIRECTORY option. It includes information in the output about the number of rows, number of variables, and table labels.
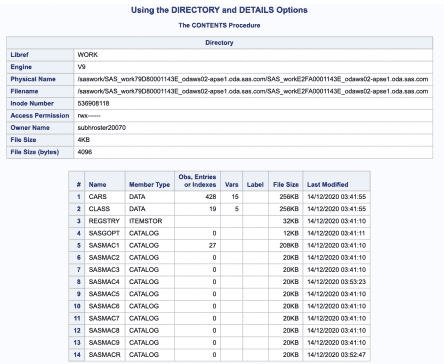
If you do not specify the DETAILS or NODETAILS option, the default for the CONTENTS procedure is the system options setting, which is NODETAILS; for the CONTENTS statement.
NOPRINT
The NOPRINT option is used to suppress the printing of the output.
VARNUM
By default, variables are listed alphabetically. The varnum option requests that SAS display the listing of the variables in the order in which they appear in the data “set”:
Below is an example of using the Varnum option in Proc contents
proc contents data=sashelp.class varnum;

ORDER=COLLATE | CASECOLLATE | IGNORECASE | VARNUM
- COLLATE prints a list of variables in alphabetical order beginning with uppercase and then lowercase names.
- CASECOLLATE prints a list of variables in alphabetical order even if they include mixed-case names and numerics.
- IGNORECASE prints a list of variables in alphabetical order, ignoring the letters’ case.
- VARNUM is the same as the VARNUM option.
SHORT
SHORT option prints only the list of variable names for the table. The list will be truncated if the variables are more than 32,767 characters, and a WARNING is written to the log. The alphabetical listing - COLLATE will give you a complete list of variables.
proc contents data=class short;title 'Using the SHORT option';run;

FMTLEN
Using this option will print the length of the informat or format. If the length for format or informat is not specified, it will not appear in the PROC CONTENTS output unless you use the FMTLEN option.
CENTILES
[Centiles](“http”://v8doc.sas.com/sashtml/proc/z0401496.htm) give you a nice overview of the distribution of your data. Print centiles information for indexed variables.
MEMTYPE=
Sometimes we will want to document all of the files in our data warehouse of a certain type. For example, we might want the directory and data set information about only the files we view.
PROC CONTENTS allows us to do so using the MEMTYPE= option. These three member types are DATA, INDEX, and VIEW. We simply set the option to a specific member type (in our example, a “VIEW”).
The syntax will look something like the “following”: proc contents data=mylib.all memtype=view;
proc contents data=work._all_ memtype=data;

Creating Output Datasets
You can create output datasets using the OUT and OUT2 options in the contents Procedure. Below is an example.
OUT=table-name names an output table. Note that OUT= does not suppress the printed output from the statement. Use the NOPRINT option to suppress the printed output.
proc contents data=sashelp.class noprint out=varnames(keep=name varnum);run;

OUT2= Use the OUT2= option if you want to print only the information about constraints and other datasets-related information.
proc contents data=class noprint out2=DatasetInfo;run;proc transpose data=DatasetInfoout=DatasetInfo_Transposed(rename=(_name_=Variables)) label=Descriptionprefix=Values;var _all_;run;proc print data=DatasetInfo_Transposed;run;
Below is the transposed output of datsetInfo.

Exporting Proc Contents output
ODS EXCEL FILE="/home/outputs/contents.xlsx"options (sheet_interval='PAGE');ods exclude directory;ods exclude members;proc contents data=work._all_ memtype=data;run;ODS EXCEL CLOSE;
Final Thoughts on Proc Contents
We can use the CONTENTS procedure to generate a detailed report of our SAS data libraries, SAS data sets, and SAS data views.
The CONTENTS procedure will document our data set columns attributes, data set and column descriptions, number of rows, indexes, creation date, modification date, and more!
Moreover, if you have other suggestions regarding tips or tricks, suggest them below the comment section. We would take those lists in our further blog post.
Thanks for reading!
If you liked this article, you might also want to read the Proc Summary Procedure and Ten Quick Uses of Proc Datasets.
Do you have any tips to add Let us know in the comments.
Please subscribe to our mailing list for weekly updates. You can also find us on Instagram and Facebook.