


Table Of Contents


One of the major strengths of SAS is its ability to work with the character data. The SAS character functions can be helpful to work with the character data like finding substring of a string, splitting a large sentence into words, converting case of characters and there are a lot many.
In this article, I have summarized most of the important SAS Character functions which can be useful to you while working with character data.
How does SAS store or determine the length of character data?
Before we start with applying character functions, it is important to understand how SAS stores any character data.
Understanding the basics will avoid some of the common pitfalls which can arise when applying the SAS character function. These can include truncation of data, Incorrect results, and even some of the errors like INVALID arguments.
In SAS variables are determined whether to be a character or numeric during the compile stage of the data step.
Example “1”: How Length of variables is determined in SAS
data example1;input var1 $ @10 var2 $3.;left='x ';/*x and 4 Blanks*/right=' ';/*4 Blanks and x*/sub=substr(var1, 1, 2);rep=repeat(var1, 1);datalines;ABCDEFGH 123XXX 4Y 5;RUN;
Let’s look at each of the character variables created in the data step by using Proc contents.
proc contents data=example1 varnum;title "proc contents for data set example1";run;
The VARNUM option requests the variables to be in the order that they appear in the SAS data set.
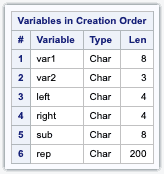
- Var1 is reading list input. Since no informat is used SAS will give a default length of 8.
- Var2 is read with an informat, the length is set to be 3.
- LEFT and RIGHT variables are created with an assignment statement. So, the length of these variables is equal to the number of bytes in the literals following the = sign.
“Note”: If a variable appears several times in a data step, its length is determined by the first reference of that variable.
IF SEX = 1 THEN GENDER = 'MALE';ELSE IF SEX = 2 THEN GENDER = 'FEMALE';
The length of GENDER in the above example is 4 since the statement in which the variable first appears defines the length. As a result, you will have GENDER = ‘FEMA’.
“TIP”: It is a good practice to use a LENGTH statement to avoid truncation of data.
LENGTH GENDER $ 6;
Continuing further, the variable SUB has a length of 8. The SUBSTR function can extract some or all of one string and assign the result to a new variable.
Since SAS has to determine variable lengths in the compilation stage, the SUBSTR arguments that define the starting point and the length of the substring could possibly be determined in the execution stage.
SAS gives the variable defined by the SUBSTR function the longest length it possibly could—the length of the string from which you are taking the substring.
Finally, the REP variable is created by using the REPEAT function. The REPEAT function takes a string and copies it as many times as provided by the second argument to the function.
Using the same logic as the SUBSTR function, since the length of REP is determined in the compile stage and since the number of repetitions could vary, SAS gives it a default length of 200.
SAS character Functions to change the case.
There are 3 SAS character functions that you can use to change the case of characters in SAS.
1. UPCASE
UPCASE function is used to change all letters to uppercase.
“Syntax”: UPCASE(character-value)
2. LOWCASE
LOWCASE changes all letters to lowercase.
“Syntax”: LOWCASE(character-value)
3. PROPCASE
PROPCASE capitalize the first letter of each word in a string.
“Syntax”: PROPCASE(character-value)
Functions to search for characters
Functions in this category are used to search a string for specific characters or for a character category (such as a digit).
The “ANY” functions
These functions have similar usage. These SAS character functions return the location of the first alphanumeric, letter, digit, punctuation, or space in a character string.
If none is found, this function returns a 0. With the use of an optional parameter, these functions can begin searching at any position in the string and can also search from right to left.
“Syntax”: Function-name (character-value <,start>)
\[su_note note_color=“#FEF9F3” radius=“1” class=“note2”]
- The start is an optional parameter that specifies the position in the string to begin the search. If it is omitted, the search starts at the beginning of the string.
- For non-zero, the search begins at the position in the string of the absolute value of the number (starting from the left-most position in the string).
- The search goes from left to right if the start value is positive and from right, to left if the start value is negative.
- A negative value larger than the length of the string results in a scan from right to left, starting at the end of the string.
[/su_note]
“TIP”: Use the TRIM function (or STRIP function) with the ANY and NOT functions since leading or, especially, trailing blanks will affect the results. For example, if X = “ABC ” (ABC followed by three blanks), Y = NOTALNUM(X) will be 4, the location of the first blank. Therefore, you may want to use TRIM or STRIP to remove the unwanted blanks. For the below examples let STRING = “ABC 123 ?xyz_n_”

The “NOT” functions
This group of functions returns the position of the first character value that is not a particular value.
As with the “ANY” functions, there is an optional parameter that specifies where to start the search and in which direction to search.
FIND, FINDC and FINDW
This pair of functions shares some similarities to the INDEX and INDEXC functions. FIND and INDEX both search a string for a given substring.
FINDC and INDEXC can be used to search for individual characters. However, both FIND and FINDC have some additional capability over their INEX and INDEXC.
In FIND and FINDC you can declare a starting position for the search, the direction of the search, and the ignore case or trailing blanks.
FIND
FIND is used to locate a substring within a string. By using arguments, you can define the starting point for the search, the direction of the search, and ignore the case or any trailing blanks.
“Syntax”: FIND(character-value, find-string <,‘modifiers’> <,start>)
The find-string argument is a character variable that contains one or more characters that you want to search for.
The function returns the first position in the character-value that contains the find-string. It returns 0 if the string is not found.
Modifiers:
- “i”: ignore the case.
- t: ignore trailing blanks in both the character variable and the find-string.
The start is an optional parameter that specifies the position in the string to begin the search. By default search starts at the beginning of the string.
If you specify a non-zero argument, the search begins at the position in the string of the absolute value of the number.
The search goes from left to right if the value is positive and right to left for negative values.
If you specify a negative value that is larger than the length of the string, the search begins from right to left, starting at the end of the string.
The function returns 0 if the value of start is a positive number or longer than the length of the string.
FINDC
FINDC locates a character that appears or does not appear within a string.
You can control the starting point for the search, the direction of the search, ignore case or trailing blanks, or look for characters except the ones listed by specifying optional arguments.
FIND is used to locate a substring within a string. By using arguments, you can define the starting point for the search, the direction of the search, and ignore the case or any trailing blanks.
“Syntax”: FINDC(character-value, find-string <,‘modifiers’> <,start>)
The function returns the first position in the character-value that contains one of the find-characters.
If none of the characters is found, the function returns a 0. With an optional argument, you can have the function return the position in a character string of a character that is not in the find-characters list.
Modifiers:
- i: ignore the case.
- t: Using this argument will ignore the trailing blanks in both the character variable and the find-characters.
- v: By specifying this argument you can count characters that are not in the list of find characters.
- o: process the modifiers and find characters only once to a specific call to the function.
FINDW
Returns the character position of a word in a string, or returns the number of the word in a string.
FINDW is used to locate a substring within a string. By using arguments, you can define the starting point for the search, the direction of the search, and ignore the case or any trailing blanks.
Syntax : FINDW(string, word, start-position <, character(s) <, modifier(s)>>)
For the complete list of FINDW modifiers, you can refer to the SAS Documentation website.
“Examples”: For these examples let STRING1 = "Hello hello goodbye" and STRING2 =“hello”
| Functions | Results |
|---|---|
| FIND(STRING1, STRING2) | 7 |
| FIND(STRING1, STRING2, ‘I’) | 1 |
| FIND(“abcxyzabc”,“abc”,4) | 7 |
| FIND(STRING1, STRING2, “i”, -99) | 7 |
| FINDC(STRING1, STRING2) | 5 |
| FINDC(STRING1, STRING2, ‘i’) | 1 |
| FINDC(STRING1,“aple”,‘vi’) | 6 |
| FINDC(“abcxyzabc”,“abc”,4); | 4 |
INDEX, INDEXC, and INDEXW
This set of functions can be used to search for One or more characters in a string.
INDEXC searches for one or more individual characters and always searches from right to left.
INDEXW To search a string for a word, defined as a group of letters separated on both ends by a word boundary (space, the beginning of a string, end of the string).
Read more on Index Function.
VERIFY
The VERIFY function is used to check if a string contains any unwanted values.
SYNTAX : VERIFY(character-value, verify-string)
VERIFY function returns the first position in the character-value which is not present in the verify string.
The function returns 0 if the character values do not contain any character other than the verify string.
| Functions | Results |
|---|---|
| VERIFY(‘ABCXABD’, ‘ABCDE’) | 4 (“X” is not in the verify string) |
| VERIFY(“ABC ”,“ABC”) | 4 (position of the 1st blank) |
| VERIFY(TRIM(“ABC ”),“ABC”) | 0 (no invalid characters) |
SAS Character Functions That Join Two or More Strings Together
SAS has three call routines and four character functions that can concatenate character strings. Although you can use the || concatenation operator in combination with the STRIP, TRIM, or LEFT functions, these routines and functions make it much easier to put strings together and, if you wish, to place one or more separator characters between the strings.
An advantage of using the call routines over their corresponding functions is improved performance. For example, CALL CATS(A, C, E, G) is faster than R = CATS(A, C, E, G).
CALL CATS
CALL CATS is used to join two or more strings. It also removes both leading and trailing blanks before the concatenation takes place.
“Syntax”: CALL CATS(result-string,string-1)
CALL CATT
CALL CATT concatenates two or more strings, removing only the trailing blanks before the concatenation takes place.
Syntax : CALL CATT(result-string,)
CALL CATX
CALL CATX is similar to CALL CATT. However, this has the facility of placing a delimiter of your choice between each of the resultant strings.
Syntax : CALL CATX(separator,result-string,string-1,)
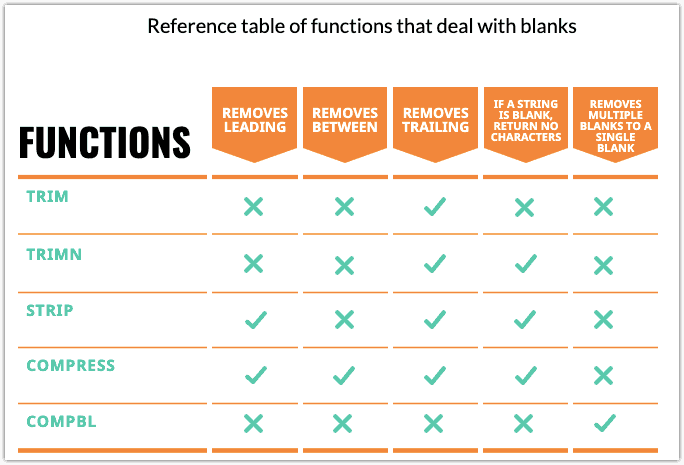
SAS Character Functions That Remove Blanks from Strings
There are times when you want to remove blanks from the beginning or end of a character string. There are two functions LEFT and RIGHT which shift the characters to the beginning of the end of the string, respectively.
The TRIM, TRIMN, and STRIP functions are useful when you want to concatenate or compare strings that have leading or trailing blanks.
SAS LEFT Function
SAS LEFT function is used to left-align text values. It doesn’t remove the leading blanks instead it moves them to the end of the string. Thus, it doesn’t change the storage length of the variable, even when you assign the result of LEFT to a new variable.
The LEFT function is particularly useful if values were read with the $CHAR informat, which preserves leading blanks.
RIGHT Function
RIGHT is used to right-align a text string. If the length of a character variable has previously been defined and it contains trailing blanks, the RIGHT function will move the characters to the end of the string and pad with blanks to the beginning. So, the final length of the variable remains unchanged.
COMPBL
COMPBL is used to replace all occurrences of two or more blanks with a single blank character. The length of the result variable will be the length of the argument if it has not been defined.
Syntax : COMPBL(charcter-value)
COMPRESS
COMPRESS function is used to remove specific characters from a character value. Similar to COMPBL, If a length has not been previously assigned, the length of the resulting variable will be the length of the argument. Read more on the compress function.
Syntax : COMPRESS(character-value,)
The compress list is an optional list of the characters you want to remove. Blanks are removed as default if no arguments are specified.
TRIM, TRIMN, and STRIP
TRIM and TRIMN both remove trailing blanks. STRIP returns both leading and trailing blanks.
TRIM
To remove trailing blanks from a character value. This is especially useful when you want to concatenate several strings together and each string may contain trailing blanks.
“Syntax”: TRIM(character-value)
The length of the variable returned by the TRIM function will be the same length as the argument unless the length of this variable has been previously defined.
If the result of the TRIM function is assigned to a variable with a length longer than the trimmed argument, the resulting variable will be padded with blanks.
TRIMN
To remove trailing blanks from a character value. This is especially useful when you want to concatenate several strings together and each string may contain trailing blanks.
Syntax : TRIMN(character-value)
SAS STRIP Function
You can use the SAS STRIP function to remove all the leading and trailing blanks from character variables or strings. STRIP(CHAR) is equivalent to TRIMN(LEFT(CHAR)).
Syntax : STRIP(character-value)
“Example”:
data RemoveBlanks;length y $ 10;string=" ABC D EF G H I ";x=TRIM(string);y=TRIM(string);TRIM='*'||TRIM(string)||'*';TRIMN='*'||TRIMN(string)||'*';STRIP='*'||STRIP(string)||'*';LEFT='*'||LEFT(string)||'*';RIGHT='*'||RIGHT(string)||'*';TRIM_LEFT='*'||TRIM(LEFT(string))||'*';TRIM_RIGHT='*'||TRIMN(RIGHT(string))||'*';COMPRESS='*'||COMPRESS(string)||'*';COMPBL='*'||COMPBL(string)||'*';run;
\[caption id="" align=“aligncenter” width=“573”]

SAS Character Functions That Compare Strings (Exact and “Fuzzy” Comparisons)
The functions in this section allow you to compare strings that are exactly similar or not exact matches.
COMPARE
The COMPARE is used to compare two character strings. There are modifiers for the COMPARE function which you can use to remove leading blanks, ignore cases, truncate the longer string to the length of the shorter string, and strip quotation marks.
Syntax : COMPARE(string-1,string-2,)
“Modifiers”:
- i ignore-case
- l removes leading blanks
- n removes quotation marks
- ”“: truncate the longer string to the length of the shorter string.
The function returns a 0 is returned when the two strings match (after any modifiers are applied).
A non-zero value is returned if the two strings differ. If string-1 comes before string-2, a negative value is returned else the positive value is returned.
Note that the order of the modifiers is important. As in the below example. The function returns a 0 when the two strings match (after any modifiers are applied).
For the below examples let string1 = “AbC”, string2 = “ABC”, string3 = ” ‘ABC’n”, string4 =“ABCXYZ”
| Function | Results |
|---|---|
| COMPARE(string1,string4) | 2 (“B” comes before “b”) |
| COMPARE(string4,string1) | -2 |
| COMPARE(string1,string2,‘i’) | 1 |
| COMPARE(string1,string4,‘:I’) | 0 |
| COMPARE(string1,string3,‘nl’) | 4 |
| COMPARE(string1,string3,‘ln’) | 1 |
CALL COMPCOST, COMPGED, and COMPLEV
COMPGED and COMPLEV are both used to determine the similarity between two strings.
The COMPCOST call routine allows you to customize the scoring system when you are using the COMPGED function.
COMPGED computes a quantity called generalized edit distance. This is useful in matching names that are not spelt exactly the same. For example JohnDoe@abc.com and John_Doe@abc.com.
Larger values indicate there are more dissimilarities between the two strings.
COMPLEV performs a similar function but uses a method called the Levenshtein edit distance. The Levenshtein edit distance measures the number of operations required for a single character to transform string-1 into string-2. Operations can be deletion, insertion, or replacement.
CALL COMPCOST
To determine the similarity between two strings, using a method called the generalized edit distance.
The cost is computed based on the difference between the two strings. Since there is a default cost associated with every operation used by COMPGED, you can use that function without using COMPCOST at all. You need to call this function only once in a data step.
For a complete list of operations and costs, you can refer to the [SAS Documentation.](“http”://support.sas.com/documentation/cdl/en/lrdict/64316/HTML/default/viewer.htm#a002206135.htm)
Syntax : CALL COMPCOST(‘operation-1’, cost-1 <,‘operation- 2’, cost-2 …>)
Operation is a keyword, placed in quotation marks. A few of the keywords are DELETE, REPLACE, SWAP, TRUNCATE. Cost is a value associated with the operation. Cost values ranges from -32, 767 to +32,767
“Example”:
CALL COMPCOST('REPLACE=', 100, 'SWAP=', 200);CALL COMPCOST('SWAP=', 150);
COMPGED
This function is used to compute the similarity between two strings, using a method called the generalized edit distance.
This function can be used in conjunction with CALL COMPCOST if you want to alter the default costs for each type of spelling error.
“Syntax”: COMPGED(string-1, string-2 <,maxcost><,‘modifiers’>)
Maxcost, is the maximum cost that will be returned by the COMPLEV function. If the cost computation results in a value larger than maxcost, the value of maxcost will be returned.
“Modifiers”:
- i ignore-case
- l remove leading blanks
- n removes quotations marks from any argument and ignore-case
- ”“: Colon modifier truncates the longer string to the length of the shorter string.
\[su_note note_color=“#FEF09B” radius=“4”]“Note”: If multiple modifiers are used, the order of the modifiers is important and they are applied in the same order as they appear.[/su_note]
| String1 | String2 | Function | Results |
|---|---|---|---|
| SAME | SAME | COMPGED(STRING1, STRING2) | 0 |
| case | CASE | COMPGED(STRING1, STRING2) | 500 |
| case | CASE | COMPGED(STRING1, STRING2,‘I’) | 0 |
| case | CASE | COMPGED(STRING1, STRING2,999,‘I’) | 0 |
| Ron | Run | COMPGED(STRING1, STRING2) | 100 |
COMPLEV
This function uses the Levenshtein edit distance method to compute the similarity between two strings.
COMPLEV is similar to the COMPGED function. However, It uses less compute resources than COMPGED function but may not do an as good job of matching misspelt names.
Syntax : COMPLEV(string-1, string-2 <,maxcost> <,‘modifiers’>)
| String1 | String2 | Function | Results |
|---|---|---|---|
| SAME | SAME | COMPLEV(STRING1, STRING2) | 0 |
| case | CASE | COMPLEV(STRING1, STRING2) | 4 |
| case | CASE | COMPLEV(STRING1, STRING2,‘I’) | 0 |
| case | CASE | COMPLEV(STRING1, STRING2,999,‘I’) | 0 |
| Ron | Run | COMPLEV(STRING1, STRING2) | 1 |
SOUNDEX
The SOUNDEX function creates a phonetic equivalent of a text string to facilitate ”fuzzy” matching. This function is often used to attempt to match names where there might be some minor spelling differences.
Syntax : SOUNDEX(character-value)
SPEDIS
The SPEDIS functions compute a “spelling distance” between two words.
The spelling distance is 0 if two words are identical.
SPEDIS assigns penalty points for each type of spelling error. For example, if the first of the two words are completely different, there is a large penalty whereas if the letters are not in order there is a smaller penalty.
The final spelling distance is also based on the length of words being matched. For a long word, a wrong letter results in a smaller score than a wrong letter in a shorter word.
“Syntax”: SPEDIS(word-1,word-2) For these examples, WORD1="Steven" WORD2 = "Stephen" and WORD3 =“STEVEN”
| Function | Returns |
|---|---|
| SPEDIS(WORD1, WORD2) | 25 |
| SPEDIS(WORD2, WORD1) | 28 |
| SPEDIS(WORD1, WORD3) | 83 |
| SPEDIS(WORD1, “Steven”) | 0 |
SAS Character Functions to Substitute Letters or Words in Strings
TRANSLATE can substitute one character from another in a string. TRNWRD can substitute a word or several words with one or more words.
TRANSLATE
Translate is used to replace one character value with another.
“Syntax”: TRANSLATE(character-value, replace-with,find-string)
“Example”:
| Function | Result |
|---|---|
| TRANSLATE(“12X45”, “ABCDE”, “12345”) | ABXDE |
| TRANSLATE(“Y”, “10”, “YN”) | 1 |
In the above example, 12345 are the characters to be translated and ABCDE is the characters to be replaced with. So, 1 is replaced with A,2 with B, 3 is not found in the character value so, X is not replaced.
TRANWRD
TRANWRD is used to replace one or more words with a replacement word.
“Syntax”: TRANWRD(character-value, find-string,replace-with)
Example:
| Function | Results |
|---|---|
| TRANWRD(“Now is the time”,“is”,“is not”) | Now is not the time |
TRANSTRN
The TRANSTRN function removes all occurrences of a substring in a given character string.
Syntax : TRANSTRN( source-expression, target-expression, replacement-expression)
Example:
data _null_;string1='*' || transtrn('abcxabc', 'abc', trimn(' ')) || '*';str="Hello World";str2='*' || transtrn(str, 'Hello', trimn(' ')) || '*';put str2;str3='*' || tranwrd(str, 'Hello', trimn(' ')) || '*';put str3;run;
In, the above example, TRANSTRN removed the first argument “Hello” whereas TRANWARD added a blank character to the string.
“Output”:
* World* * World*
SAS Character Functions that compute the length of strings
There are four character functions that can compute the length of character values.
LENGTH function returns the length of a given string. It does not count trailing blank in its calculation.
LENGTHN functions return a value of 0 if there is a null string whereas LENGTH function returns 1.
The LENGTHC functions count trailing blanks in its computation.
LENGTHM is used to compute the length used to store this variable in memory.
Read : SAS Length Functions : LENGTH / LENGTHN / LENGTHC / LENGTHM
SAS Character Functions to count the number of letters or substrings in a string
The COUNT function counts the number of times a given string appears in a string while the COUNTC function counts the number of times specific characters occur in a string.
COUNT
This character function number of times a given substring appears in a string. The case can be ignored by using modifiers. If no occurrences of the substring are found, the function returns a 0.
“Syntax”: COUNT(character-value, find-string <,‘modifiers’>)
“Modifiers”:
- i : Ignore-case
- t : Ignores trailing blanks in both character value and the find string.
COUNTC
COUNTC is used to count the number of individual characters that appear or do not appear in a string. With the use of a modifier, the case can be ignored.
There is another modifier in the COUNTC function which allows you to count characters that do not appear in the string. It returns 0 if specified characters are found.
Syntax : COUNTC(character-value, characters <,‘modifiers’>)
“Modifiers”:
- i: Ignore-case
- t: Ignores trailing blanks in both character value and the find string.
- o: This modifier process the characters or modifiers only once.
- v: This modifier is used to count only the characters that do not appear in the character value.
| Functions | Results |
|---|---|
| COUNT(“ding and dong”,“g “) | 1 |
| COUNTC(“ABCDEabcde”,“BCD”,‘VI’) | 4 (A, E, a, and e) |
Other useful Functions
QUOTE and DEQUOTE
The QUOTE function inserts double quotation marks to a string. If double quotation marks are already found within the argument, they are doubled in the output.
“Example”:
str1="hello world";str2=quote(str1);str3=dequote(str2);put str1 str2 str3
OUTPUT:
hello world "hello world" hello world
The DEQUOTE functions remove quotes from a string. The DEQUOTE, COMPRESS, and TRANSTRN functions can each be used to remove quotes.
DEQUOTE not only removes pairs of quotes but will also truncate the remainder of the string. COMPRESS and TRANSTRN can replace all occurrences without looking for quote pairs.
When you apply the DEQUOTE function, the following things happen.
\[su_note note_color=“#FEF9F3” radius=“1” class=“note2”]
- If there are no quotation marks, there is no change in the output.
- No leading quotes there is no change in the output.
- Matching double and single quotation marks are removed from the resultant string.
- Paired double and single quotation marks are reduced to one.
- Single or double quotation marks inside single/double quotation marks are unchanged.
- If there are unmatched double quotes, the quotes are removed.
- Unmatched single quotes remain unchanged
- Any text which is placed after the matching quotes mark is deleted.
[/su_note]
“Example”:
string1 = "'CA', ""OR"", 'WA'";dq1 = dequote(string1);string1 = "'CA', ""OR"", 'WA'";dq1 = dequote(string1);dq1=CA
In the above example, DEQUOTE removes the quotes from CA and truncates the remainder of the string.
WHICHC
The WHICHC function is used to search through a given list of arguments and return the index of the first one that matches the given list.
The count starts with the second argument. If the second argument matches the first argument it returns 1 if it matches with the third argument it returns 3. If no match is found in the list, it returns 0. If multiple matches are found, it returns the index of 1st matched argument.
“Syntax”: WHICHC(string, value-1 <, value-2, …>)
Example:
Fruits=whichc('apple','orange','pear','apple','apple','fig');put Fruit=;
Fruit=3
CHOOSEC
The CHOOSEC function returns the value of the index provided in the first argument. If a negative index is given, the function counts backwards in the list and return that value.
“Syntax”: CHOOSEC (index-expression, selection-1 <,…selection-n>)
Example:
Fruit=choosec(2,'apple','orange','pear','fig');put Fruit=;
Fruit=orange
MISSING
This function is used to determine if a charter or numeric argument is missing. The function return1 if the value is missing else it returns 0.
COALESCEC
The COALESCEC accepts one or more character arguments and then returns the first non-missing value from a list of character arguments. This function may be useful if you have a long list of values but may require finding the first non-missing value.
“Syntax”: COALESCEC(argument-1 < …, argument-n>)
“Example”:
y = COALESCEC ('','Hello', 'World');put y;
y=Hello
RANK
The RANK function is used to obtain the relative position(ASCII) of the characters.
This can be useful if you want to associate each character with a number so that an ARRAY subscript can point to a specific character.
“Example”:
RANK("A") returns 65 and RANK("a") returns 97
REPEAT
The REPEAT function is used to make multiple copies of a string.
“Syntax”: REPEAT(character-value, n)
n is the number of repetitions. The result of this function s the original string plus n repetitions.
“Example”:
REPEAT("HELLO ",3) returns HELLO HELLO HELLO HELLO
SAS REVERSE Function
SAS REVERSE function can be used for advanced string manipulation SAS. The REVERSE function is used to reverse the order of text of a character value. The output variable length is given the length of its first argument if the input variable length is not defined in a DATA step.
\[su_note note_color=“#FEF09B” radius=“4”]“Note”: Trailing blanks in the argument become leading blanks in the result.[/su_note]
“Syntax”: REVERSE(character-value)
“Example”:
REVERSE("ABCDE")
would return
EDCBA