A weighted average is a way of determining a set of numbers that considers each number’s importance. To get a weighted average, multiply each number in the data set by a chosen weight.
A weighted average can be more accurate than a simple average in which all numbers in a data set are assigned an identical weight.
The weighted average can be calculated in SAS using PROC SQL, PROC MEAN, PROC UNIVARIATE, or a Data Step.
PROC SQL is the first method for calculating the weighted average in SAS. The code is simple. You simply write down the weighted average formula. In other words, you divide the sum of the weights multiplied by the scores by the amount of the weights.
proc sql;
create table weighted_average as select sum(weight * score) /
This method requires the most code and is the most complex. Nevertheless, as SAS analyses data row-by-row, this method can create a rolling weighted average.
sum wt includes the sum of the weights of all preceding rows, including the current row, in the example given below.
The column sum wt x score displays the sum of the weights multiplied by the row’s scores. rolling weighted average contains the rolling average up until a particular row. The final weighted rolling average is the weighted average of the entire dataset.
PROC MEANS is a popular and powerful SAS technique for analysing numerical data fast. Each numeric column displays by default the number of observations, the mean, the standard deviation, the minimum, and the maximum.
In the first line of code, you invoke PROC MEANS and define the input data. You also specify that you want the sum, the sum of weights, and the mean to be calculated.
Using the weight keyword in the second line instructs SAS to calculate the weighted mean rather than the normal mean.
The var keyword specifies for which variable the sum and weighted mean are to be calculated.
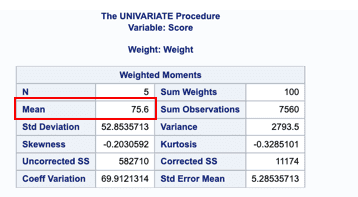
The SAS procedure PROC UNIVARIATE examines the distribution of your data, including the evaluation of normalcy and the discovery of outliers. PROC UNIVARIATE displays more statistical information than PROC MEANS by default.
The PROC UNIVARIATE code for calculating the weighted mean is easy. You can indicate that all calculated statistics must be weighted using the weight keyword. The var keyword indicates to SAS which variable to analyse.
This section discusses four approaches for calculating the weighted average for each group in SAS.
This section’s examples utilise a dataset containing the scores of two students. Each student received a score for five distinct assignments with varying weights. We are interested in the weighted mean score per student.
PROC SQL is the first approach for calculating the weighted average per group.
This is the easiest technique, especially if you are already familiar with SQL. We use the GROUP BY clause to determine the weighted average for each student.
proc sql;
create table weighted_average as select students, sum(weight * score) /
sum(weight) as weighted_average from score_data_students group by students;
A SAS Data Step is one of the methods for calculating the weighted average per group.
The first step in calculating the weighted average is to sort the dataset by the column containing student names.
proc sort data=score_data_students;
by students assignments;
run;
The code below computes a weighted rolling average for each student.
data rolling_weighted_average;
set score_data_students;
by students;
retain sum_weight sum_score;
if first.students then
do;
sum_weight=weight;
sum_score=score * weight;
rolling_weighted_avg=sum_score / sum_weight;
end;
else
do;
sum_weight=sum(sum_weight, weight);
sum_score=sum(sum_score, score * weight);
rolling_weighted_avg=sum_score / sum_weight;
end;
keep students rolling_weighted_avg;
if last.students then
output;
run;
SAS will calculate a weighted rolling average for each student. However, just the last row per student is of importance to us. We use the KEEP option and the LAST keyword to select the last row for each student and only the columns of interest.
In the following SAS code, the data= option is used to define the input dataset. With the sum, sumwgt, and mean, we direct SAS to calculate particular statistics.
Using the CLASS keyword, the second line of code calculates the statistics (e.g., the weighted mean) independently for each student.
We tell SAS to generate the weighted mean of the score variable using the WEIGHT keyword.
proc means data=work.my_data sum sumwgt mean nway;
The data= option is used in the following SAS code to define the input dataset. SAS is instructed to compute specific statistics using the sum, sumwgt, and mean.
Using the CLASS keyword, the second line of code calculates the statistics independently for each student (e.g., the weighted mean).
By employing the WEIGHT keyword, we instruct SAS to calculate the weighted mean of the score variable.