


Table Of Contents


SQL Set operators are conceptually derived from the mathematical set principle. The three fundamental set operators are UNION, INTERSECT, and EXCEPT.
All three, with variations (in particular, OUTER UNION) and options, could be carried out in PROC SQL to combine data from several tables in the SQL procedure.
Joins VS SQL SET Operators
Before we delve into the main points of PROC SQL set operators, let’s set up the basic distinctions between joins and set operators.
DATA first;A = 1;RUN;DATA second;B = 2;RUN;
So each of these tables has one row and one column. You can use a PROC SQL step to combine the two through a simple cross “join”:
SELECT *FROM first, second
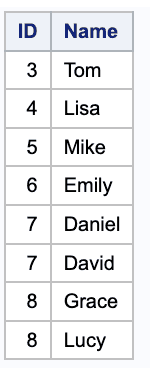
Now, look at the UNION, which is the simplest type and probably the most extensively used of the SQL set operators. The code to combine our two tables “is”:
SELECT *FROM firstUNIONSELECT *FROM second
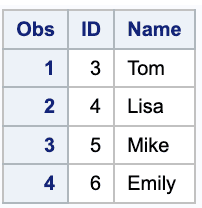
UNION is inserted between two SELECTs (each of which has, as it should, a subordinate FROM clause). A set operator works on the outcomes of two SELECTs. This is unlike a join, carried out inside the FROM clause of a single SELECT.
See the two numeric values, this time arranged vertically rather than horizontally. This demonstrates the fundamental difference between joins and set operators.
Joins align rows and accrete columns, whereas set operators align columns and accrete rows.
This is something of an oversimplification. SQL just isn’t a matrix language and provides comparatively little symmetry between rows and columns. So, the distinction between joins and set operators are barely a basis for the main points to observe.
Rules for SET operators
Set operators adhere to fundamental guidelines of operation.
If a SELECT statement consists of multiple set operators, set operators will likely be applied in the order specified.
By default, duplicate rows are eliminated from the results.
The ALL option should be specified with a set operator to allow duplicates.
Arguments are evaluated from left to right.
Set operators can be used “in”:
- Queries
- Subqueries
- Derived tables
- View definitions
- INSERT with SELECT clause
SQL Operators and Precedence
Set operators adhere to an order of precedence. The following precedence rules “apply”:
When a multiple set operator is specified, each is applied in the order “specified”:
Top to bottom
to right
The default order of precedence for processing set operators is as “follows”:
INTERSECT
UNION and/or EXCEPT
When parentheses are specified, the default order of precedence could be altered.
Data Type Compatibility
The alignment of columns in these examples has laboured smoothly because the aligned columns have matched concerning the data type (numeric or character).
Since column alignment is an important aspect of virtually all the set operators, it’s worth exploring this a bit more.
DATA num;id = 3;worth = 0;RUN;DATA char;id = 4;worth = 'abc';RUN;
VALUE is numeric in the data set NUM, but a character in the data set CHAR. So once you try a DATA step concatenation with
DATA both;SET num char;RUN;
SAS will give this log “message”:
The new data set (BOTH) is created but contains no observations.
If you run the parallel SQL “code”:
CREATE TABLE both ASSELECT *FROM numOUTER UNION CORRESPONDINGSELECT *FROM char;
"ERROR": Column 2 from the first contributor of OUTER UNIONis not the same type as its counterpart from the second.
Unlike the DATA step, PROC SQL doesn’t even create an empty table in this scenario.
There is only one set operator resistant to data type mismatches because it does no column alignment; that’s the OUTER UNION operator without the CORRESPONDING option.
Accessing Rows from the Intersection of Two Queries (INTERSECT)
The INTERSECT operator creates query results that consist of all of the distinctive rows from the intersection of the two queries.
Put another approach, the intersection of two queries (A and B) is represented by C, which signifies that the produced rows occur in A and B.

proc sql;select * from sashelp.prdsalewhere precise < 20intersectselect * from sashelp.prdsalewhere prodtype = "OFFICE";quit;
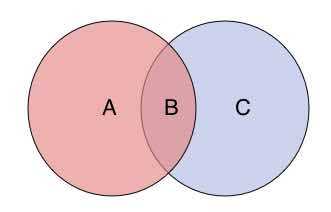
It is assumed that the tables in each query are structurally identical because the wildcard character is specified within the SELECT assertion.
The INTERSECT operator produces rows that are widespread to each query.
Accessing Rows from the Combination of Two Queries (UNION)
The UNION operator preserves all the distinctive rows from the combination of queries.
The result is identical, as if an OR operator is used to combine the results of each question. Put another approach, the union of two queries (A and B) represents rows in A, B, or both A and B.

The UNION operator automatically eliminates duplicate rows from the results until the ALL keyword is specified as a part of the UNION operator. The column names assigned to the results are derived from the names in the first query.
To achieve success, each query should specify the same number of columns of the same or compatible types for the union of two or more queries.
Type compatibility signifies that column attributes are defined the same way. Because column names and attributes are derived from the primary table, data types should be the same. The data types of the result columns are derived from the source table(s).
proc sql;select * from sashelp.prdsalewhere actual < 5intersectselect * from sashelp.prdsalewhere prodtype = "OFFICE";quit;

Concatenating Rows from Two Queries (OUTER UNION)
The OUTER UNION operator concatenates the results of two queries. The results include vertically combined rows as with a DATA step or PROC APPEND concatenation.
Put another way, the outer union of two queries (A and B) represents all rows in both A and B with no overlap.

The OUTER UNION operator automatically concatenates rows from two queries with no overlap until the CORRESPONDING (CORR) keyword is specified as a part of the operator.
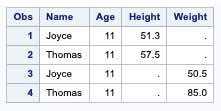
proc sql;create table combine asSELECT name,age,height FROM sashelp.class where age <12OUTER UNIONSELECT name,age,weight FROM sashelp.class where age < 12;quit;
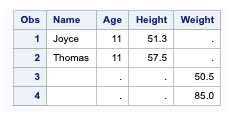
The column names assigned to the results are derived from the names in the first query. In the following example, the CORR keyword enables table columns with the same name and attributes to be overlaid.
proc sql;create table combine asSELECT name,age,height FROM sashelp.class where age <12OUTER UNION corrSELECT name,age,weight FROM sashelp.class where age < 12;quit;
Comparing Rows from Two Queries (EXCEPT)
The EXCEPT operator compares rows from two queries to find out the modifications made to the primary table that aren’t present in the second table.
The following results show new and altered rows in the first table in the second table however don’t show rows that were deleted from the second table.
When working with two tables with similar data, you need to use the EXCEPT operator to find new and modified rows.
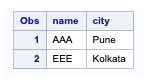
/*table one*/data table1;input name $ city $;datalines;AAA PuneBBB DelhiCCC MumbaiEEE Kolkata;run;/*table 2*/data table2;input name $ city $;datalines;AAA PatnaBBB DelhiCCC MumbaiDDD Bangalore;run;/*Using Except Operator*/proc sql;create table checkdata asselect * from table1except select * from table2;quit;
 Table1
Table1
 Table 2
Table 2
The EXCEPT operator determines rows in the first table (or a question). However, shouldn’t be used to determine rows in the second table (or query).
It also uniquely identifies rows modified from the primary table to the second table. Columns are compared within the order that they appear in the SELECT statement.
The “Takeaway”:
So, this was our side on SQL SET Operators. We hope that you must have found it useful.
Moreover, if you have other suggestions, mention them in the comment section below. We would take those lists in our further blog post.
Thanks for reading!
If you liked this article, you might also want to read A Comprehensive Guide To PROC SQL In SAS (15 + Examples) and Intermediate Proc SQL Tutorials With Examples.
Do you have any tips to add? Let us know in the comments.
Please subscribe to our mailing list for weekly updates. You can also find us on Instagram and Facebook.