


Table Of Contents


The SAS INDEX function searches for a specified string of characters. If any match is found, the INDEX function returns 0 or the position of the first occurrence of the string’s first character.
The basic INDEX function has two arguments, source and excerpt. The source is the character string variable or expression you would like to search, and the excerpt is the character string you want to search within the source.
INDEX function has two variations - INDEXC and INDEXW, and you need to decide which one to use in which scenarios. Typical usage of the SAS INDEX function is to find things in a character variable.
This article covers the INDEX, INDEXC and INDEXW functions and helps you understand the concepts and use cases of the INDEX function.
SAS Index Function
The SAS INDEX function searches the source string, from left to right, to find the first occurrence of the string specified in the excerpt, and returns the position in the source of the string’s first character.
If the string is not found in the source, INDEX returns a value of 0. If there are multiple occurrences of the string, INDEX returns only the position of the first occurrence.
Syntax
INDEX(source-string, excerpt)
Example
In the below example, the INDEX function is used to find the position of ‘o’ in the source string - ‘Hello World’.
data _null_;s='Hello World';p='o';a=index(s, p);put a=;run;
x=5

Note that the INDEX function returns the position of the excerpt’s first character the first time it is found, so it returns 5.
Index Function in a SAS dataset
The INDEX function can also search variables within a SAS dataset. In the SASHELP.CARS dataset, the MODEL variable contains car model names.
Let’s say, for example, you would like to know if the word “manual” occurs within the MODEL variable.
data find_manual;set sashelp.cars(keep=model);manual=index(model, 'manual');run;

Ignoring case when using the INDEX function
The index function is a case-sensitive search. So if you are not sure about the case in the source string, you can use the UPCASE or LCASE function with the INDEX function to ignore the case while performing the search.
The UPCASE function temporarily converts the variable model to uppercase and then uses the index function to search for the key phrase - ‘MODEL.’
data find_manual;set sashelp.cars(keep=model);manual=index(upcase(model), 'MANUAL');run;
Removing Trailing Spaces When You Use the INDEX Function with the TRIM Function
If you use INDEX without the TRIM function, leading and trailing spaces are considered part of the excerpt argument.
If you use INDEX with the TRIM function, TRIM removes trailing spaces from the excerpt argument, as seen in this example. Note that the TRIM function is used inside the INDEX function.
data _null_;a = ' Hello World';x = index(a,'o');y = index(strip(a),'o');put x= y=;run;
x=6 y=5
If there are leading or trailing spaces in the search string, use the Index function as below.’
data _null_;a = 'Hello World';b = ' o';x = index(a,b);y = index(a,strip(b));put x= y=;run;
x=0 y=5
INDEXC Function
Searches a character expression for any of the specified characters and returns the position of that character.
The INDEXC function searches for the first occurrence of any individual character present within the character string, whereas the INDEX function searches for the first occurrence of the character string as a substring.
The FINDC function provides more options.
Syntax
INDEXC(source-string, excerpt1<, …excerpt-n>)
data _null_;a = 'Hello World';x = indexc(a,'o','l');put x=;run;
x=3

Note that, even though o is found at position 5, INDEXC returns the position of l that is 3. This is how the INDEXC function works - It always returns the position of the first found character in the source string.
If you specify multiple characters to the index function argument, it still returns the position of the first character it founds in the source.
In the below example, the Indexc function returns the position of 2 because it has found the character ‘e’ at the 2nd position in the variable a.
data _null_;a = 'Hello World';x = indexc(a,'o','el','lm');put x=;run;
x=2
See the below example; It makes no difference if you list the search characters as ‘oel’ or ‘o’,‘e’,‘l’. INDEXC functions return 2.
data _null_;a='Hello World';x=indexc(a, 'oel');y=indexc(a, 'o', 'e', 'l');put x=y=;run;
x=2 y=2
Another use case of Indexc function
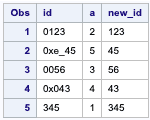
Consider a scenario where a character variable contains leading zeros followed by some number. You want to create a new variable without the leading zeros.
In this case, you can use the INDEXC to get the position of any numbers except 0. Then you have to use that position in SUBSTR function - 2nd argument to extract the string.
data test;input id $;a=indexc(id, '123456789');new_id=substr(id, a);datalines;01230xe_4500560x043345;run;
Reading dates in a mixture of formats.
In some cases, your input date may contain dates in a mixed format, as shown below.
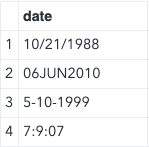
Also, you can see that dashes and colons are used besides a slash. Any string that includes a slash, dash, or colon is a date that needs the MMDDYY10. informat. Otherwise, DATE9. informat can be used.
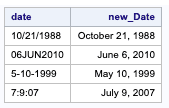
Here, INDEXC is used to check if the data contains ’/’,’-’ or ’:’ and apply the appropriate informat to the date.
Read :
data mixed_dates;input @1 date $15.;if indexc(date,'/-:') then new_Date = input(date,mmddyy10.);else new_Date = input(date,date9.);format new_Date worddate.;datalines;10/21/198806JUN20105-10-1999"7":"9":07;run;
INDEXW Function
The INDEXW function searches the source, from left to right, for the first occurrence of the character and returns the position in the source of the substring’s first character.
If the substring is not found in the source, then INDEXW returns a value of 0. If there are multiple occurrences of the string, then INDEXW returns only the position of the first occurrence.
In INDEXW, the substring pattern must begin and end on a word boundary. For INDEXW, word boundaries are delimiters, the beginning and end of the source.
Note - Punctuation marks are not word boundaries.
In INDEXW you can use the third argument, the delimiter, to specify which delimiter is used to separate words. Space is the default delimiter, and If you use an alternate delimiter, then INDEXW does not recognise the end of the word unless the delimiter is given in the third argument.
Syntax
INDEXW(source-string, excerpt <, delimiters>)
Example
data _null_;s='Apples Apricots Avocados';p='Apricots ';a = indexw(s,'cots');b=indexw(s, p);put a= b=;run;
a=0 b=8
INDEXW has the following behaviour when the second argument contains blank spaces or has a length of “0”:
- If both source and excerpt string contain only blank spaces, then INDEXW returns 1.
- If the excerpt contains only blank spaces, then INDEXW returns a value of 0.
data _null_;s=' ';s1='Apples Apricots Avocados';p=' ';a=indexw(s,p); /*Source is blank, search is blank - Returns 1*/b=indexw(s1,p); /*Search is blank - Returns 0*/put a=b=;run;
a=1 b=0
Using the Delimiter Argument with INDEXW
data _null_;s='Apples,Apricots,Avocados';p='Apricots';a=indexw(s, p,",");put a=;run;
a=8
What is the difference between find and index in SAS?
This is one of the common questions asked in a SAS Interview.
The FIND function and the INDEX function both search for substrings of characters in a character string. However, the INDEX function does not have any modifier. For example, the FIND functions have the ability to declare a starting position for the search, set the direction of the search, and ignore case or trailing blanks.
Key Takeaway
INDEX and INDEXW are similar, the difference being that INDEXW looks for a word (defined as a string bounded by spaces or the beginning or end of the string), while INDEX simply searches for the designated substring.
INDEXC searches for one or more individual characters and always searches from left to right.
- These three functions are all case-sensitive and
- Include leading and trailing blanks while searching.
- Searches from Left to right
References