


Table Of Contents


Sorting the data is always a resource-intensive operation. Therefore, using the PROC SORT procedure efficiently can save you both time and computing resources.
There are a number of options associated with PROC SORT that can be used to control the performance and capabilities of the procedure as well as the resulting data set.
The NODUPREC Option in Proc Sort
The NODUPREC option (as well as its aliases NODUPLICATES and NODUP) is used far too often.
You might think that using this option will remove all duplicate observations, and although this is what it nominally is supposed to do, it does not necessarily cause PROC SORT to remove all duplicate observations.
In fact, it only removes duplicate observations that are adjacent after sorting.
When the sorting process results in a data set in which duplicate observations are not next to each other (they do not come one after the other sequentially), they will not be detected and the duplicate observation(s) will not be removed.
data SortExample;input Subject visit "labdt":mmddyy8. sodium chloride;format labdt mmddyy8.;datalines;200 1 07/06/2006 140 103200 2 07/13/2006 144 106200 1 07/06/2006 140 103200 4 07/13/2006 140 103200 4 07/13/2006 140 103200 5 07/07/2006 142 104;run;

proc sort data=SortExample out=sorted noduprecs;by subject;run;

The row Observation number 4 is removed, and a NOTE is added to the log. Observation numbers 1 and 3 are also duplicates but are ignored by the option.
"NOTE": There were 6 observations read from the data set WORK.SORTEXAMPLE."NOTE": 1 duplicate observations were deleted."NOTE": The data set WORK.SORTED has 5 observations and 5 variables.
When key fields in the BY statement are sufficient to form a primary key that can uniquely identify the observations within a BY group, it will make the NODUPREC option work as we would hope that it would.
In the last example, we can get rid of the duplicate record by adding the BY statement to VISIT, LABDT, and SUBJECT.
proc sort data=SortExample out=sorted noduprecs;by subject visit labdt;run;
You may also specify the _all_ option, which will remove the duplicate rows.
"NOTE": There were 6 observations read from the data set WORK.SORTEXAMPLE."NOTE": 2 duplicate observations were deleted."NOTE": The data set WORK.SORTED has 4 observations and 5 variables.
NODUPKEY and DUPOUT options
The NODUPKEY option checks and eliminates observations with duplicate BY values keeping only the first occurrence in the BY group.
proc sort data=SortExample nodupkey;by visit;run;

Note that, all the duplicate records within the same BY group (Visit) have been removed.
When the NODUPREC or the NODUPKEY options are used, the LOG will note when observations are removed.
However, which observations were removed will not be written in the LOG.
If you want to be able to see these observations, the **DUPOUT**= option can be used to save the duplicate observations into a separate data set.
proc sort data=SortExample out=sorted nodupkey dupout=dup1;by visit;run;
NOUNIQUEKEY and UNIQUEOUT options
The NOUNIQUEKEY option checks and eliminates observations from the output data set that has a unique sort key.
A sort key is unique when the observation containing the key is the only observation within a BY group.
proc sort data=SortExample nouniquekey out=dupsreq uniqueout=uniqreq;by visit;run;

Duplicate records were deleted from the original dataset. You can save the duplicate records in another dataset by using the OUT option.
If option OUT is not used, the original dataset is overwritten and will contain only the duplicate records.
The **UNIQUEOUT**= option can be used with the NOUNIQUEKEY option. UNIQUEOUT\= SAS-data-set specifies the output data set for observations that will contain unique records.

OVERWRITE
The OVERWRITE option will enable you to delete the input data set before the replacement output data set of the same name is populated with observations.
Using this option can reduce disk space requirements.
PRESORTED
The PRESORTED checks within the input data set to determine whether the sequence of observations is in order before sorting is done.
Use the PRESORTED option when you know or strongly suspect that a data set is already in order according to the key variables that are specified in the BY statement.
Using this option can eliminate the unnecessary overhead of the cost of sorting the data set.
Maintaining the Relative Order of Observations in Each BY Group
The EQUALS option specifies the order of the observations in the output data set and it maintains the relative order of the observations from within the input data set to the output data set for observations with identical BY variable values.
NOEQUALS does not necessarily preserve this order in the output data set.
The SORTEQUAL and NOSORTEQUALS are the two system options that control whether the first observation in a group is selected or not.
SORTEQUAL specifies that observations with identical BY variable values are to retain the same relative positions in the output data set as in the input data set.
NOSORTEQUALS says that no resources should be used to control the order of observations in the output data set that have the same value for a BY variable.
EQUALS Option
The EQUALS option sorts the observations by the value of the first variable and maintains the relative order.
To understand this, let’s look at the example below.
data One;input ID 1 Number 3-5;datalines;5 4215 3361 2091 5643 7113 3434 2124 616;title "original";proc print;
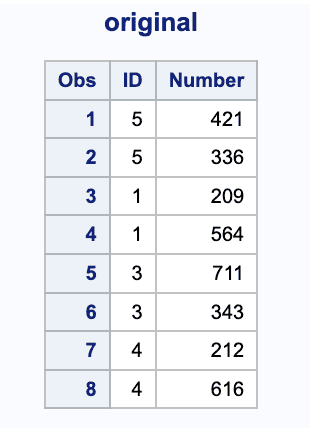
proc sort data=one out=one_sorted equals;by ID;run;proc print data=one_sorted;title 'Sorting with EQUALS Option';run;
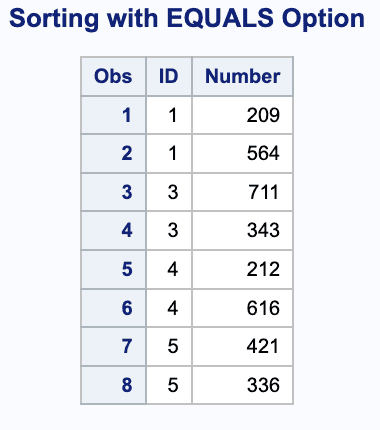
Using the EQUALS option, which is also the default, the Sort procedure maintains the order of the By variables which is also the first observation in the BY group.
proc sort data=example nodupkey noequals;by id;run;

NOEQUALS Option
By default, the order of data in the same by-groups is preserved. The NOEQUALS option sorts the observations by the value of the first variable, but it doesn’t keep the order of the variables’ relative positions.
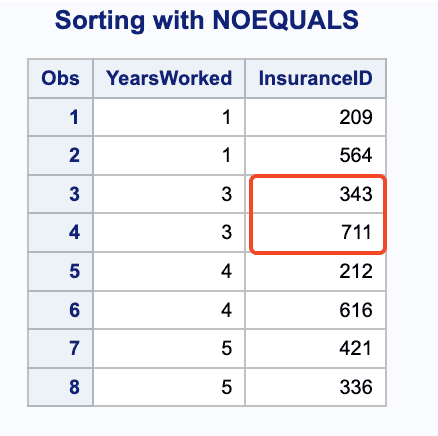
Note that sorting with the EQUALS option versus sorting with the NOEQUALS option causes a different sort order for the observations where ID=3.
Handling of observations with duplicate keys
PROC SORT with the NODUPKEY option removes records with identical keys. However, this has been enhanced, and now you have the ability to choose which of the observations is kept, and you can send the duplicates that aren’t kept to a dataset.
The following examples use a dataset containing customer ID numbers and the quantity purchased in a month.
data orders;input custid qty month $6.;datalines;10270 5 JAN12230 4 JAN19323 7 JAN19323 3 FEB22779 2 FEB22779 2 FEB28819 4 FEB29252 1 FEB30457 9 MAR30457 1 APR30457 3 MAY30457 2 MAY31918 1 MAY31918 1 MAY30457 2 JUN;run;

Let’s suppose, you need to find customers who have an order quantity of more than one for a given month.
You can proc sort step as below which will sort the data based on custid and month and the unique orders are kept in the dataset. The duplicate observation is sent to a different dataset using the dupout option.
proc sort data=orders out=sort1 nodupkey dupout=dups;by custid month;run;

Note, that the output in the dataset specified in DUPOUT option gives us the 1st records for each BY group. What if we want to have all the duplicate values in the output dataset?
Using, the NOUNIQUE key and UNIQUE out option you can have all the duplicate values as below which is also the output we want. i.e. all customers who have more than one order quantity in a month.
proc sort data=orders nouniquekeys out=alldups uniqueout=uniques;by custid month;run;
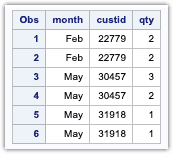 The contents of alldups dataset
The contents of alldups dataset
This combination can be used instead of the First and last dataset variables and in a few lines of code. Below are all the unique records that are stored in the unique dataset.

SORTSEQ
PROC SORT uses the ‘[collating sequence](“http”://support.sas.com/resources/papers/linguistic_collation.pdf)’ to determine the sorted order of values.
There are two commonly used collating sequences, EBCDIC (for mainframe systems) and ASCII (for most other machines running Operating Systems like Windows and UNIX).
You have long been able to select one or the other of these two different collating sequences by specifying the EBCDIC or ASCII options on the PROC SORT statement.
The SORTSEQ option allows you to further refine the way the selected collating sequence is used.
This includes subsets or locals within a national collating sequence. Even without changing the base collating sequence, the SORTSEQ option can be beneficial.
You can get more information on using Linguistic Collation options of Proc sort in the below article.