


Table Of Contents


In today’s data-driven world, it is common to have multiple tables containing similar data but with slight variations.
When working with these tables, it is important to compare them to make sure they are correct and consistent.
In SAS, there are several ways to compare two tables, including using the “PROC COMPARE” procedure or writing SQL queries.
Comparing tables can help identify differences in data, inconsistencies, and other issues that may need to be addressed. In this blog post, we will explore how to compare two tables in SAS.
Assuming you have two datasets or tables named table1 and table2, you may want to compare them to see which rows have been updated, which rows are unique to one table, and which rows are common to both tables.
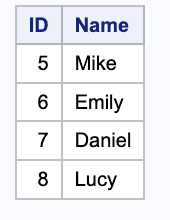
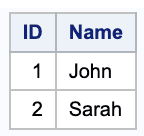
/* Create table1 */data table1;input ID Name $;datalines;1 John2 Sarah3 Tom4 Lisa7 David8 Grace;run;proc print;/* Create table2 */data table2;input ID Name $;datalines;1 John2 Sarah5 Mike6 Emily7 Daniel8 Lucy;run;
Finding New and Updated Rows in a “Table”: Using Set Operators in SQL
You can use set operators such as union, intersect, and except to compare two tables in SQL and find the updated rows. Here’s an example Proc SQL query that uses the EXCEPT operator to find the updated “rows”:
proc sql;title "Updated Rows";select * from table2exceptselect * from table1;quit;
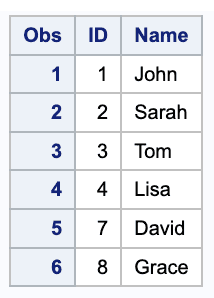 Table 1
Table 1
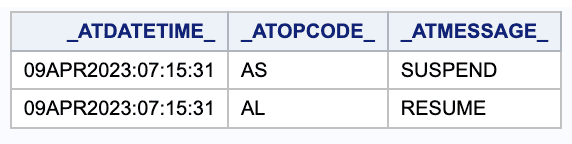 Table 2
Table 2
 Updated Rows
Updated Rows
In this query, the EXCEPT operator will return all the rows from table2 that are not in table1. These are the rows that have been updated in table2.
However, it’s important to note that using set operators may not be the most efficient method for large datasets, as it requires comparing all rows in both tables. Using JOIN or PROC COMPARE may be more efficient for large datasets with a large number of rows.
Finding New and Updated Rows in a “Table”: Using Data step Merge
A data step merge is a powerful SAS feature that enables you to combine two or more datasets based on a common variable. The resulting dataset contains all the records from both tables, and you can easily identify new and updated rows.
To demonstrate this, let’s assume we have two datasets - Table1 and Table2 - that we want to compare. Each table has a unique identifier variable called ID, and a variable called Name.
First, we will sort both datasets by all variables using PROC SORT. This step is necessary for a successful merge.
proc sort data=Table1;by _all_;run;proc sort data=Table2;by _all_;run;data merged;merge table1(in=a) table2(in=b);by _all_;if not a;run;
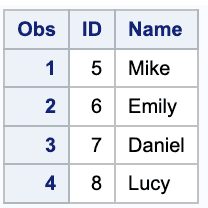
Finding only Updated Rows in a “Table”: Using Inner Join
To find out which rows have been updated in table2, you can use a SQL query to compare the two tables based on their primary keys.
The query will join table1 and table2 on their primary keys, and then select only the rows where the values of at least one column differ between the two tables.
Here’s an example SQL “query”:
proc sql;SELECT table2.*FROM table1INNER JOIN table2ON table1.id = table2.idWHERE table1.name table2.name;quit;

In this query, we are selecting all columns from table2 where the id matches between the two tables, and the name column is different between the two tables. This will give us a result set containing only the rows in table2 that have been updated.
Finding Unique Records in Two “Tables”: Using Set Operators in SQL
Here’s an example SQL query to find records that are unique in both tables
proc sql;SELECT 'table1' as TableName,ID, Name FROM table1WHERE ID NOT IN (SELECT ID FROM table2)UNIONSELECT 'table2' as TableName,ID, Name FROM table2WHERE ID NOT IN (SELECT ID FROM table1);quit;

In this query, the ”NOT IN” operator is used to select records that exist in one table but not in the other. The ”UNION” operator is used to combine the results of the two SELECT statements into a single result set.
This query selects the “ID” and “Name” columns from “table1” and “table2” and returns the records that are unique to each table. Specifically, it returns the records where the ID is not present in the other table.
To find all the unique records in both tables using set operators, you can use the UNION operator along with the EXCEPT operator. Here’s an example SQL “query”:
proc sql;SELECT id, nameFROM table1UNIONSELECT id, nameFROM table2EXCEPTSELECT id, nameFROM table1INTERSECTSELECT id, nameFROM table2;quit;
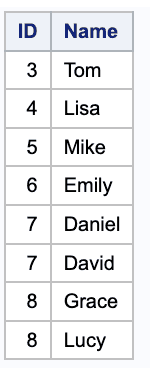
Finding Unique Records in Two “Tables”: Using SQL JOIN Operations
To find records that are unique in both tables, you can use a FULL OUTER JOIN to combine the two tables and then filter for rows where one side of the join is NULL. Here’s an example SQL “query”:
proc sql;SELECT COALESCE(t1.ID, t2.ID) AS ID,CASE WHEN t1.Name IS NULL THEN 'N/A' ELSE t1.Name END AS Name1,CASE WHEN t2.Name IS NULL THEN 'N/A' ELSE t2.Name END AS Name2,CASE WHEN t1.ID IS NULL THEN 'Table2 Only'WHEN t2.ID IS NULL THEN 'Table1 Only'ELSE 'Different Names' END AS StatusFROM table1 t1FULL OUTER JOIN table2 t2ON t1.ID = t2.IDWHERE t1.Name t2.Name OR t1.Name IS NULL OR t2.Name IS NULL;quit;
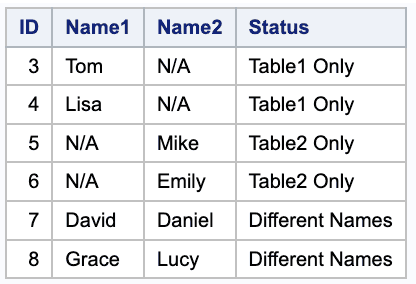 Finding Unique Records in Two Tables
Finding Unique Records in Two Tables
In this query, the FULL OUTER JOIN operator returns all rows from both tables, matching rows from both tables where the IDs match, and NULL values for non-matching rows. The COALESCE function is used to select the ID from the non-null table.
The WHERE clause is used to filter the results to only include the rows where either the ID is missing from table1 or missing from table2, indicating that the record is unique to one table.
Finding Unique Records in Two “Tables”: Using Datastep Merge
Here’s an example SAS code to find unique records in two tables using datastep merge.
proc sort data = table1;by id;run;proc sort data = table2;by id;run;data merged2;merge table1(in=a) table2(in=b);by id;if (a and not b) or (not a and b);run;proc print;
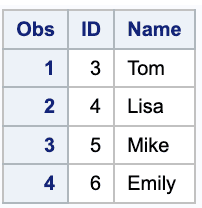
Find the common records in two tables
To find the common rows in two tables using SQL set operators, you can use the INTERSECT operator. The INTERSECT operator returns only the rows that appear in both tables.
Here’s an example SQL “query”:
proc sql;SELECT * FROM table1INTERSECTSELECT * FROM table2;quit;
This query will return all the common rows between table1 and table2. If you only want to select specific columns, you can replace * with the column names.
Note that both tables must have the same number of columns and compatible data types for the INTERSECT operator to work properly.
Find the common records in two tables using Data step Merge
To find the common records in two tables using Data step Merge, you can use the code below.
proc sort data = table1;by _all_;run;proc sort data = table2;by _all_;run;data MergedTable;merge Table1 (in=a) Table2 (in=b);by _all_;if a and b;run;proc print;
Find the common and different records in two tables
In this SQL query, we are first using the same ”FULL OUTER JOIN” as in the previous query to find the differences between the two tables. We are then using the ”UNION” operator to combine the results with another SQL query that uses an ”INNER JOIN” to find the common records in both tables.
proc sql;SELECT COALESCE(t1.ID, t2.ID) AS ID,CASE WHEN t1.Name IS NULL THEN 'N/A' ELSE t1.Name END AS Name1,CASE WHEN t2.Name IS NULL THEN 'N/A' ELSE t2.Name END AS Name2,CASE WHEN t1.ID IS NULL THEN 'Table2 Only'WHEN t2.ID IS NULL THEN 'Table1 Only'ELSE 'Different Names' END AS StatusFROM table1 t1FULL OUTER JOIN table2 t2ON t1.ID = t2.IDWHERE t1.Name t2.Name OR t1.Name IS NULL OR t2.Name IS NULLUNIONSELECT t1.ID, t1.Name, t2.Name, 'Common Names'FROM table1 t1INNER JOIN table2 t2ON t1.ID = t2.IDWHERE t1.Name = t2.Name;quit;

The first part of the SQL query will show the ID values, Name values for each table, and the Status indicating the differences between the two tables.
The second part of the SQL query will show the ID values and Name values that are present in both tables, with the Status column indicating “Common Names”.
After executing this SQL query, the result will show the common and different records in both tables. The “Status” column will indicate whether the row is present in both tables, only in table1, only in table2, or if the Name values are different.
Conclusion
In conclusion, comparing two tables in SAS can be done in many ways. One approach is to use SQL queries with different operators like JOIN, UNION, INTERSECT, and EXCEPT to find the differences and similarities between the tables.
Another approach is to use SAS procedures like PROC COMPARE, which can be helpful in finding differences between two tables in a more structured and organized way.